【算法2】基础+贪心
BST && BBST
从根开始搜索。
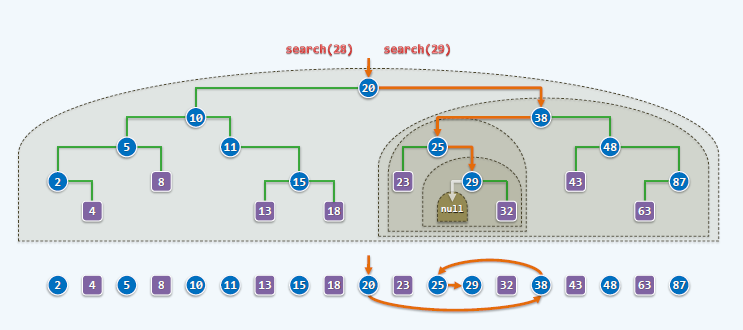
所有的左后代都小于父代,右后代都大于父代,才能满足。
Balance Binary Search Tree, 平衡二叉搜索树,能够更好的提高搜索效率。
散列表
这里,我们先讨论一下散列表(哈希表),作为一个数组,可以很快的查找到。哈希冲突,是需要处理的,可以用链进行链接。
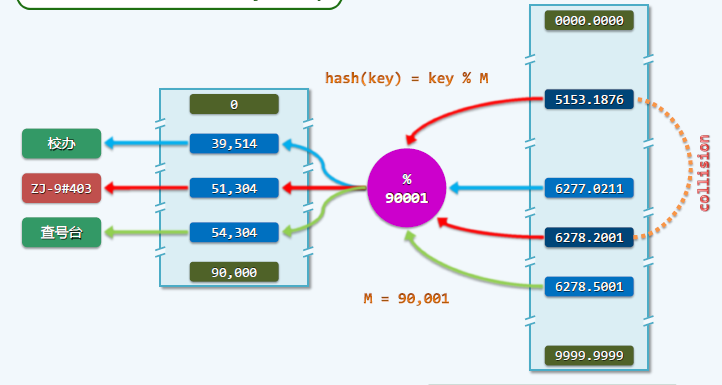
取模一般使用素数,为什么使用素数?(如果对一个合数取模,那么对其某个因数取模,结果可能仍然一致。例如 10 对 8 取模,结果为 2,对 4 取模,结果也为 2。而我们对一个素数取模,由于素数只有 1 和其本身两个因素,即不可能出现上述情形。)
Hashtable are also used in Dictionary and Map.
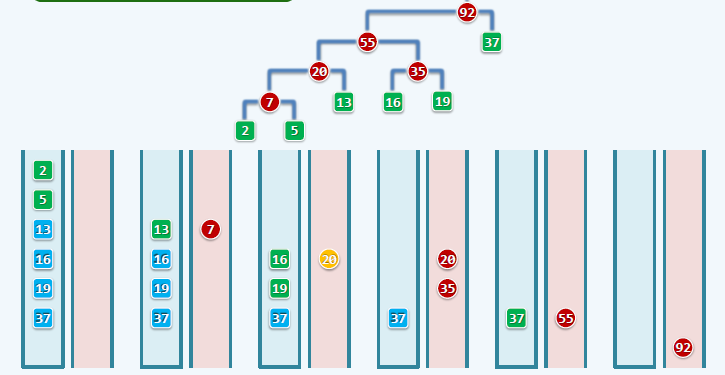
Huffman Tree 2
回顾之前的Huffman Trees, 如何进行排序?
我们引入优先队列。
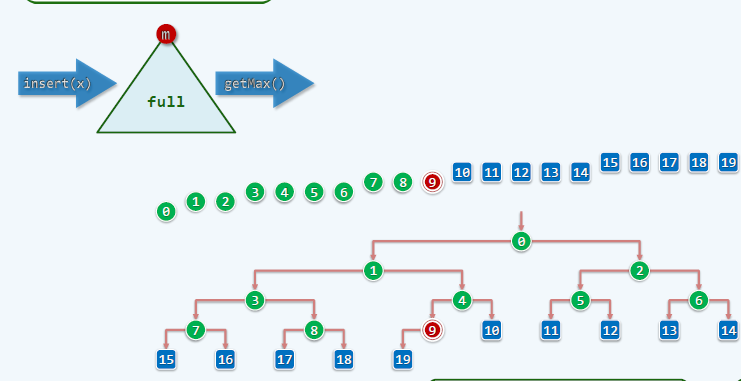
我们同样可以使用Stack+Queue的方式。
首先将需要编码的数进行排序,存入Stack中,之后取出2个相加,存入队列中。
a) 比较stack.pop() 和 queue.dequeue(), 取出最小的两个。
b) 将两数相加,存入队列。
直到合并为最后一个。
Minimum Spanning Tree 最小生成树
Prim: cut + cross
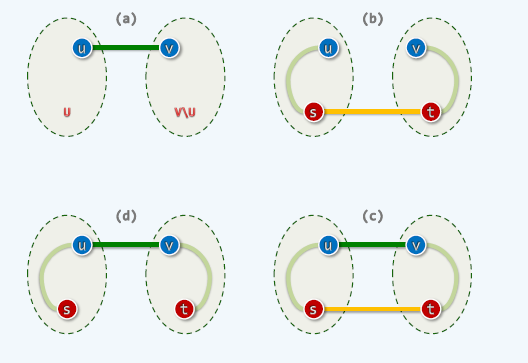
Prim算法
输入:一个加权连通图,其中顶点集合为V,边集合为E;
初始化:Vnew = {x},其中x为集合V中的任一节点(起始点),Enew = {},为空;
重复下列操作,直到Vnew = V:
a. 在集合E中选取权值最小的边
b. 将v加入集合Vnew中,将
输出:使用集合Vnew和Enew来描述所得到的最小生成树。
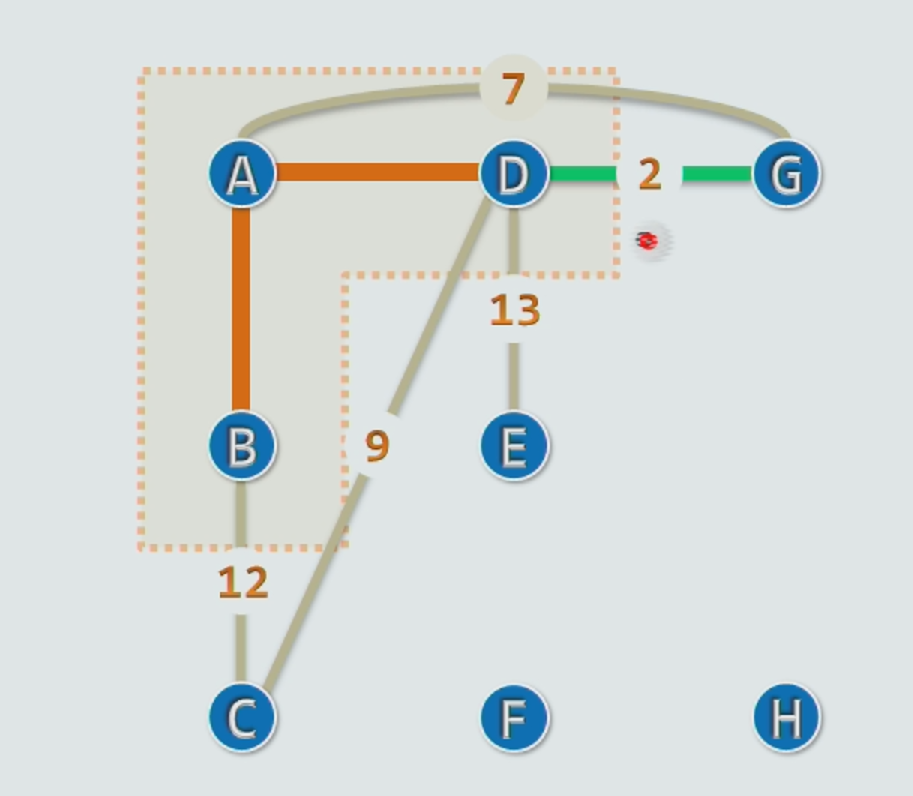
矩阵实现的话,效率会低